Pinecone
Querying Overview
Pinecone’s native query interface uses a programmatic interface to retrieve data. The general use case is to identify an index with the data of interest. Next a vector of values is required to indicate a point in n-space from which to locate similar data. It is recommended that the query set at most how many items to retrieve as well.
Qarbine provides 2 query options for Pinecone:
- JSON query structure and
- SQL-like request.
The latter is an interface that resides above the JSON query structure API. It can be more convenient to specify criteria using SQL than the more complex JSON structure approach. Most of the Pinecone features are still accessible when using the SQL syntax so there is no loss of Pinecone features or complex middleware in play.
One way to specify a Pinecone query in Qarbine is to use a JSON-like structure which looks like the following.
{
topK: 2,
vector: [...],
filter: { …}
}
The number of values in the vector must correspond to the same number within the index’s underlying data. Qarbine only performs data retrieval. There is purposely no delete or update interactions provided.
The overall general form of the syntax used by Qarbine is shown below
{
index : "sample-movies", ← This is required.
nearText: "dracula", ← Set this or the vector field below.
useAssistant: "anAiAssistant",
useEmbedding: [...], ←
returnNoValues: true, ← The default is true.
namespace: "my-namespace", ← Optional.
query: { ← This maps to a standard Pinecone query object.
topK: 2, ← At most how many matches to return.
No more than 100 will be returned anyway.
includeMetadata: true, ← The default is true.
vector: [...], ← The list of n-space numbers.
filter: { … } ← Optional metadata filtering.
}
}
Either the outer useEmbedding field is defined or the inner vector field. If a useEmbedding value is set then the named Qarbine AI Assistant service is used to obtain the vector argument to use with the effective Pinecone query. This service is set up by the Qarbine administrator.
The returnNoValues field is a boolean indicating if the data’s “values” field should be returned. Usually this is not useful for Qarbine analytic and presentation purposes and it just adds bulk to the resulting reply. The default is true to not return them.
The namespace field is used when interacting with a Pinecone index that spans multiple namespaces. An example using JavaScript syntax is shown below,
const index = pinecone.index(“sample-movies);
const queryResponse = await index.namespace('example-namespace').
query({
topK: 10,
vector: [0.1, 0.2, 0.3, 0.4],
sparseVector: { indices: [3], values: [0.8] }
})
For more details on sparse and dense vectors see
https://docs.pinecone.io/docs/query-data#querying-vectors-with-sparse-and-dense-values
The query field general maps to the Pinecone query as described at
The optional Pinecone metadata filtering is described at
In brief, metadata field filtering offers a subset of operators similar to MongoDB. These operators can be combined with $and and $or.
| Operator | Description |
|---|---|
| $eq | Equal to (number, string, boolean) |
| $ne | Not equal to (number, string, boolean) |
| $gt | Greater than (number) |
| $gte | Greater than or equal to (number) |
| $lt | Less than (number) |
| $lte | Less than or equal to (number) |
| $in | In array (string or number) |
| $nin | Not in array (string or number) |
Prerequisites
Prior to using Qarbine’s embeddings(...) macro function or the SQL-like query function nearText(...), the Qarbine Administrator must first configure “AI Assistant(s)”. The AI Assistants provide access to various popular Generative AI services and are referenced using an alias. Check with your Qarbine administrator for which ones are available and their proper use. For example, when using dynamic query vector embeddings, the model used by the AI Assistant must be compatible with the one used to generate the original embedding values in the database.
Qarbine SQL Interface
Qarbine provides a convenient SQL interface to retrieve Pinecone data and avoid the cumbersome manual authoring of Pinecone filters. The Qarbine SQL interface below translates the SQL clauses into the equivalent native Pinecone filter structure. Use the explain feature described below to confirm this. If things are not what you expect, then use the JSON structure interface.
The WHERE criteria is translated into the equivalent Pinecone filter. The operators supported are listed in the section above. The metadata filtering limitation above still applies. The basic format is
FROM <index> ← Required.
WHERE … ← Required. See below.
ORDER BY <metadata field> [ASC | DESC] ← Optional.
LIMIT <how many> ← The maximum and default is 1000.
The ALIAS above refers to an AI Assistant alias as configured by the Qarbine administrator. This is important so that the model used to generate the embedding is compatible with that used to create the stored values.
The base WHERE clause can take several forms:
vector = (number 1, number n ...) ← A different way of expressing nearVector()
nearVector(number1, number n …)
nearText(aPhrase)
nearText(aPhrase, aiAssistantAlias)
Note that a SQL numeric list is enclosed in parentheses while one in the specification is enclosed in brackets. That is a subtle nuance across the SQL and JSON syntax standards.
The table below describes their use.
| Function | Description |
|---|---|
| nearVector | This clause is removed from the WHERE criteria and its list of numbers argument set into the “nearVector” field of the query specification. |
| nearText | This clause is removed from the WHERE criteria and its argument set into the “nearText” field of the query specification. |
| withOption | Pass in the specification field name and the value to set. This clause is removed from the WHERE clause. This is commonly used to set the annsField. |
| withOptions | Set several specification fields at once. The format is withOptions(key1, value1, keyN, valueN).The key argument may use dot notation when setting the inner value of a component object. |
The nearText() parameters are described below.
| Parameter | Description |
|---|---|
| aPhrase | A quoted value for which a vector is first obtained by Qarbine and then passed along as the raw vector value. |
| aiAssistantAlias | Refers to an AI Assistant alias as configured by the Qarbine administrator. This is important to consider so that the model used to generate the raw vector value is compatible with that used to create the stored values. |
The elements of the SQL statement are extracted and used as parameters to the standard native Pinecone interface previously discussed. The returnNoValues argument is always true. The index value may be of the form indexName.namespace. If so then the namespace value is sent to Pinecone. The WHERE clause may have additional criteria starting with “AND”. The default ordering is by score, highest first.
The SQL query below
select * from sample-movies
where nearText( 'two girls' ) and "box-office" > 102030405
order by summary desc
limit 2
is equivalent to
#pragma sortResultBy summary desc
{
"index": "sample-movies",
"returnNoValues": true,
"nearText": "two girls",
"query": {
"includeMetadata": true,
"filter" : {
"box-office":{ "$gt" : 102030405}
},
"topK": 2
}
}
Notice the dashed field names are enclosed in double quotes. Also, Qarbine data retrieval tools have a default LIMIT which can be overridden. In this case by specifying topK.
Here is an example that uses SQL to generate the native Pinecone query which then performs post processing to sort the results by title.
select * from sample-movies
where embeddingNear('two girls')
and "box-office" > 102030405
and year in (2009, 2018)
order by title
limit 10
Reviewing the Generated Specification
You can enter criteria of the form “EXPLAIN SELECT ….” to have the SQL statement processed and have the returned answer set be the underlying query specification. When you want to see the effective Pinecone query specification simply precede your SELECT statement with the “explain ” text. A convenient way of specifying this is to have “explain” on the first line and the rest of your SQL on the next lines.
explain
select *
from "sample-movies"
where nearText( 'two girls')
and withOption('foo', 123)
and withOption('bar', (1,2,3) )
Then simply “comment out” the first line when not in use
// explain
select *
from "sample-movies"
where nearText( 'two girls')
and withOption('foo', 123)
and withOption('bar', (1,2,3) )
You can also use “explain: true” in the JSON query specification for similar information.
Another way to get the specification is to press ALT and click  . Below is a sample result.
. Below is a sample result.
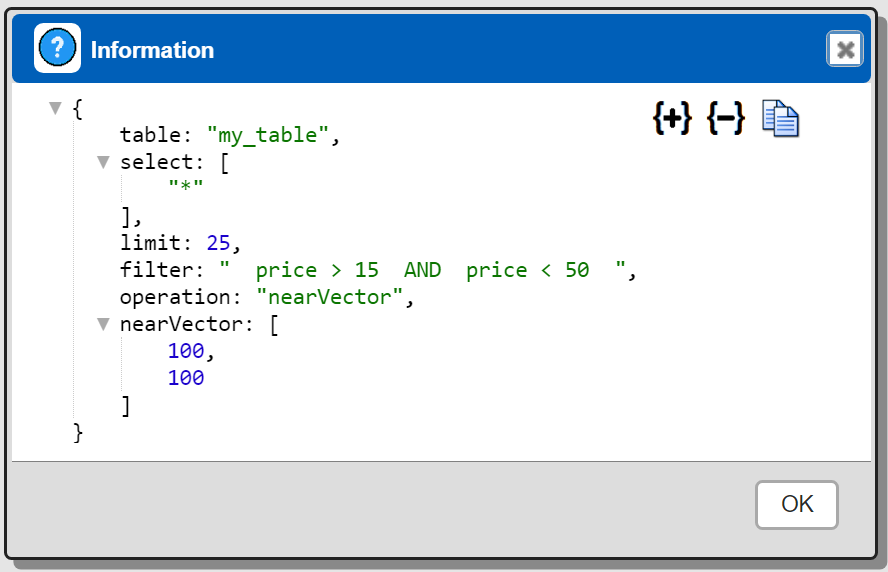
Any “explain SELECT” or “explain: true” takes precedence over the ALT-click interaction.
Qarbine Virtual Queries
There are a few convenience queries which are mainly DBA oriented. These queries are recognized by the Qarbine driver and provide common database information.
| Query | Description |
|---|---|
| list databases | Return a list of databases. |
| list indexes | Return a list of Pinecone collections. |
| describe indexes | Provide details on all of the indexes. This may take a while depending on your database structure. |
| describe index COLLECTION | Provide details on the given index. |
See the “DBA Productivity” section of the online documentation for more details.
Troubleshooting
Using the explain approach above can be very helpful resolving unexpected results. In addition, if you see
A call to https://api.pinecone.io/indexes/sample_movies returned HTTP status 404.
Pinecone error PineconeNotFoundError
Verify the index name sample_movies
then it is likely the spec’s index name or the SQL’s table name is incorrect. For example this query references the wrong table
select * from sample_movies
where nearText('two girls')
limit 10
and results in
A call to https://api.pinecone.io/indexes/sample_movies returned HTTP status 404.
Pinecone error PineconeNotFoundError
Verify the index name sample_movies
Whereas this is the correct table reference with a dash in the name
select * from sample-movies
where nearText('two girls')
limit 10
References
See the following pages for more information on querying Pinecone
https://docs.pinecone.io/guides/data/query-data
https://docs.pinecone.io/guides/data/filter-with-metadata